

1. 캐시(Cache), 캐싱(Caching)이란?
캐시(Cache)
원본 저장소보다 빠르게 가져올 수 있는 임시 데이터 저장소를 의미한다.
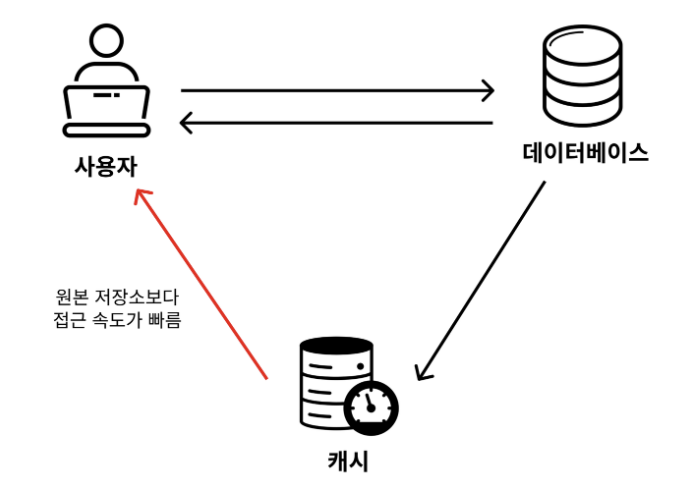
원본 데이터베이스에 접근해 데이터를 가져오는 건 시간이 오래 걸린다. 보통 최근 접근한 페이지 등이 다시 접근될 확률이 높기 때문에 속도가 빠르거나 사용자와 거리가 가까운 임시 저장소를 두고, 최근에 접근한 이미지나 파일 등의 데이터를 빨리 가져올 수 있게끔 하는 게 좋다.
예를 들어 크롬 같은 검색 도구에서도 방문한 페이지에 있던 이미지나 파일 등을 캐시(저장)해놓고 해당 페이지 재방문 시 캐시된 이미지 및 파일을 불러와 빠르게 페이지가 뜰 수 있도록 한다.
캐싱(Caching)
캐시(임시 데이터 저장소)에 접근해 데이터를 빠르게 가져오는 방식을 의미한다.
예를 들어 실무에서는 API 응답 속도가 너무 느리다면 조회 속도를 향상기 위해 응답 데이터를 캐싱해 두고 쓰는 경우가 많다.
2. 데이터를 캐싱할 때 사용하는 전략 (Cache Aside, Write Around)
Redis를 캐시로 쓸 때 쓸 수 있는 전략은 아주 다양하다. 그중에서 실무에서 가장 많이 사용되는 2가지만 알아보고 나머지 전략들은 익숙해진 뒤 추가로 학습하면 된다. 다양한 전략을 같이 사용할 수도 있다.
Cache Aside (= Look Aside, Lazy Loading) 전략
데이터를 조회할 때 주로 사용하는 전략이다.
Cache Aside 전략은 데이터 요청이 들어오면 캐시(Cache)에서 데이터를 확인하고, 없다면 DB를 통해 조회해오는 방식이다.
캐시에서 데이터 여부를 먼저 확인하기 때문에 Look Aside 전략이라고도 부르고, Cache Miss인 경우에만 Redis에 저장하기 때문에 Lazy Loading 전략이라고도 부른다. 그림으로 표현해 보면 아래와 같다.
예시를 통해 이해해보자.
서비스를 처음 배포한 경우, 사용자가 입력한 데이터는 DB에만 저장된다. 이후 사용자가 데이터 조회를 요청하면 DB에서 바로 조회를 하기 전 Redis에 해당 데이터가 있는지 확인한다.
- 데이터를 요청했을 때 캐시(Redis)에 데이터가 있는 경우를 Cache Hit이라고 한다.
- 이 경우 원본 데이터베이스에 접근하지 않고도, Redis에 저장된 데이터를 통해 빠르게 조회할 수 있다.
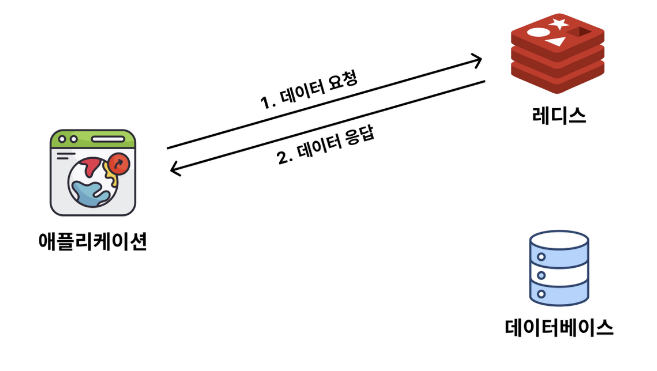
- 데이터를 요청했을 때 캐시(Redis)에 데이터가 없는 경우를 Cache Miss라고 한다.
- Redis에 데이터가 없는 걸 확인한 뒤, DB로부터 데이터를 조회해 응답한다.
- DB로부터 조회한 데이터를 응답한 뒤에, Redis에도 데이터를 저장해 둔다. (Caching)
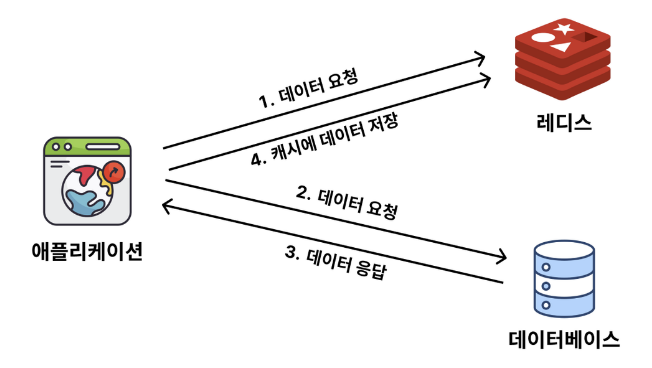
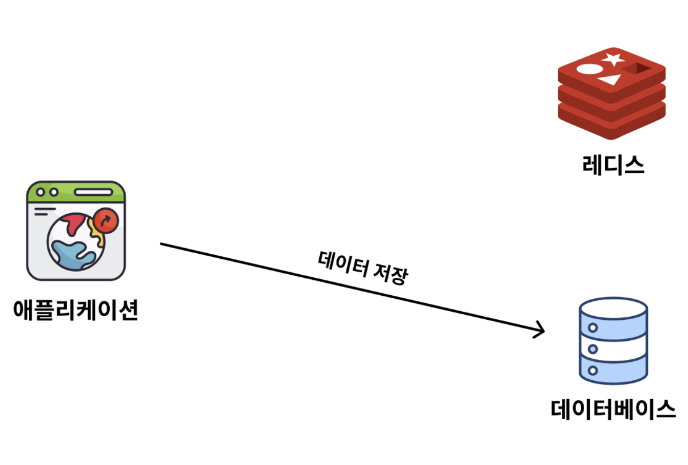
Write Around 전략
데이터를 어떻게 쓸지(저장, 수정, 삭제)에 대한 전략이다. Cache Aside 전략과 자주 같이 활용된다.
Write Around 전략은 쓰기 작업(저장, 수정, 삭제)을 캐시에는 반영하지 않고, DB에만 반영하는 방식을 뜻한다.
쓰기 작업 결과를 DB에만 우선 저장하다가, 데이터를 조회할 때 Redis에 데이터가 없으면(Cache Miss) DB로부터 데이터를 조회해 와서 Redis에 저장(Caching)하는 방식이다.
- 데이터를 저장할 때 Redis와 DB 모두에 저장하는 전략도 있지만, 실무에선 Write Around 전략이 더 자주 사용된다.
3. Cache Aside, Write Around 전략의 한계와 해결 방법 - TTL 기능
데이터 일관성 문제
a. 한계
캐시된 데이터와 DB에 저장된 데이터가 일치하지 않을 수 있다.
Write Around 전략은 데이터를 저장, 수정, 삭제할 때 DB만 갱신하기 때문에 갱신이 일어나면 기존에 Redis에 저장된 데이터 값과 DB에 저장된 데이터의 값은 다를 수밖에 없다.
b. 해결 방안 (TTL 기능)
Redis와 DB의 데이터를 일치시키기 위해 데이터 갱신이 일어날 때마다 동시에 업데이트하면 성능이 느려지게 된다.
데이터 조회 성능 개선 목적(Caching)으로 Redis를 쓰는 경우엔 데이터의 일관성을 포기하고 성능 향상을 택하게 된다. 이런 이유로 캐시를 적용하기에 적절한 데이터는 아래와 같다.
- 자주 조회하는 데이터
- 잘 변하지 않는 데이터
- 실시간으로 정확하게 일치하지 않아도 되는 데이터
장기간 데이터가 일치하지 않는 건 문제가 될 수 있기 때문에 적절한 주기로 Redis와 DB의 데이터를 동기화해야 한다. 이때 활용하는 기능이 Redis의 TTL 기능(만료 시간 설정 기능)이다.
- TTL이 설정된 데이터는 설정한 시간이 지나면 자동으로 Redis에서 삭제된다. 이후 특정 사용자가 조회하는 순간 Cache Miss가 발생하게 되고, DB에서 데이터를 새로 조회해 Redis에 다시 저장한다. TTL을 통해 데이터를 주기적으로 갱신할 수 있게 된다.
저장 공간 크기 문제
a. 한계
DB는 디스크에 저장하기 때문에 많은 양을 저장할 수 있지만, Redis는 메모리에 저장하기 때문에 DB에 비해 많은 양을 저장할 수 없다.
b. 해결 방안 (TTL 기능)
위에서 말한 TTL 기능을 활용하면 주기적으로 Redis가 비워지므로 공간을 효율적으로 사용할 수 있다.
4. 캐싱으로 조회 성능을 개선하기 전 'SQL 튜닝'을 항상 먼저 해야 한다!
데이터 조회 성능을 개선하는 방법은 다양하다.
- SQL 튜닝
- 캐싱 서버 활용 (Redis 등)
- 레플리케이션 (Master/Slave 구조)
- 샤딩
- DB 스케일업 (CPU, Memory, SSD 등 하드웨어 업그레이드)
이때 많은 성능 개선 방법 중 'SQL 튜닝'을 가장 먼저 고려해야 하는 이유는 아래와 같다.
- SQL 튜닝을 제외한 나머지 방법은 추가적인 시스템을 구축해야 하므로 금전적, 시간적 비용이 발생하게 된다. 또, 조금 더 복잡해진 시스템 구조로 인해 관리 비용도 늘어난다. 그에 비해 SQL 튜닝은 기존의 시스템 변경 없이 성능을 개선할 수 있다.
- 근본적인 문제를 해결하는 방법이 SQL 튜닝일 가능성이 높다. SQL 자체가 비효율적으로 작성됐다면 아무리 시스템적으로 성능을 개선한다고 하더라도 한계가 있다. SQL 튜닝을 통해 기본적인 성능을 향상한다면 시스템적인 성능 개선이 필요 없거나 훨씬 간단하게 큰 성능 개선 효과를 얻을 수 있다.
1. 캐시(Cache), 캐싱(Caching)이란?
캐시(Cache)
원본 저장소보다 빠르게 가져올 수 있는 임시 데이터 저장소를 의미한다.
원본 데이터베이스에 접근해 데이터를 가져오는 건 시간이 오래 걸린다. 보통 최근 접근한 페이지 등이 다시 접근될 확률이 높기 때문에 속도가 빠르거나 사용자와 거리가 가까운 임시 저장소를 두고, 최근에 접근한 이미지나 파일 등의 데이터를 빨리 가져올 수 있게끔 하는 게 좋다.
예를 들어 크롬 같은 검색 도구에서도 방문한 페이지에 있던 이미지나 파일 등을 캐시(저장)해놓고 해당 페이지 재방문 시 캐시된 이미지 및 파일을 불러와 빠르게 페이지가 뜰 수 있도록 한다.
캐싱(Caching)
캐시(임시 데이터 저장소)에 접근해 데이터를 빠르게 가져오는 방식을 의미한다.
예를 들어 실무에서는 API 응답 속도가 너무 느리다면 조회 속도를 향상기 위해 응답 데이터를 캐싱해 두고 쓰는 경우가 많다.
2. 데이터를 캐싱할 때 사용하는 전략 (Cache Aside, Write Around)
Redis를 캐시로 쓸 때 쓸 수 있는 전략은 아주 다양하다. 그중에서 실무에서 가장 많이 사용되는 2가지만 알아보고 나머지 전략들은 익숙해진 뒤 추가로 학습하면 된다. 다양한 전략을 같이 사용할 수도 있다.
Cache Aside (= Look Aside, Lazy Loading) 전략
데이터를 조회할 때 주로 사용하는 전략이다.
Cache Aside 전략은 데이터 요청이 들어오면 캐시(Cache)에서 데이터를 확인하고, 없다면 DB를 통해 조회해오는 방식이다.
캐시에서 데이터 여부를 먼저 확인하기 때문에 Look Aside 전략이라고도 부르고, Cache Miss인 경우에만 Redis에 저장하기 때문에 Lazy Loading 전략이라고도 부른다. 그림으로 표현해 보면 아래와 같다.
예시를 통해 이해해보자.
서비스를 처음 배포한 경우, 사용자가 입력한 데이터는 DB에만 저장된다. 이후 사용자가 데이터 조회를 요청하면 DB에서 바로 조회를 하기 전 Redis에 해당 데이터가 있는지 확인한다.
- 데이터를 요청했을 때 캐시(Redis)에 데이터가 있는 경우를 Cache Hit이라고 한다.
- 이 경우 원본 데이터베이스에 접근하지 않고도, Redis에 저장된 데이터를 통해 빠르게 조회할 수 있다.
- 데이터를 요청했을 때 캐시(Redis)에 데이터가 없는 경우를 Cache Miss라고 한다.
- Redis에 데이터가 없는 걸 확인한 뒤, DB로부터 데이터를 조회해 응답한다.
- DB로부터 조회한 데이터를 응답한 뒤에, Redis에도 데이터를 저장해 둔다. (Caching)
Write Around 전략
데이터를 어떻게 쓸지(저장, 수정, 삭제)에 대한 전략이다. Cache Aside 전략과 자주 같이 활용된다.
Write Around 전략은 쓰기 작업(저장, 수정, 삭제)을 캐시에는 반영하지 않고, DB에만 반영하는 방식을 뜻한다.
쓰기 작업 결과를 DB에만 우선 저장하다가, 데이터를 조회할 때 Redis에 데이터가 없으면(Cache Miss) DB로부터 데이터를 조회해 와서 Redis에 저장(Caching)하는 방식이다.
- 데이터를 저장할 때 Redis와 DB 모두에 저장하는 전략도 있지만, 실무에선 Write Around 전략이 더 자주 사용된다.
3. Cache Aside, Write Around 전략의 한계와 해결 방법 - TTL 기능
데이터 일관성 문제
a. 한계
캐시된 데이터와 DB에 저장된 데이터가 일치하지 않을 수 있다.
Write Around 전략은 데이터를 저장, 수정, 삭제할 때 DB만 갱신하기 때문에 갱신이 일어나면 기존에 Redis에 저장된 데이터 값과 DB에 저장된 데이터의 값은 다를 수밖에 없다.
b. 해결 방안 (TTL 기능)
Redis와 DB의 데이터를 일치시키기 위해 데이터 갱신이 일어날 때마다 동시에 업데이트하면 성능이 느려지게 된다.
데이터 조회 성능 개선 목적(Caching)으로 Redis를 쓰는 경우엔 데이터의 일관성을 포기하고 성능 향상을 택하게 된다. 이런 이유로 캐시를 적용하기에 적절한 데이터는 아래와 같다.
- 자주 조회하는 데이터
- 잘 변하지 않는 데이터
- 실시간으로 정확하게 일치하지 않아도 되는 데이터
장기간 데이터가 일치하지 않는 건 문제가 될 수 있기 때문에 적절한 주기로 Redis와 DB의 데이터를 동기화해야 한다. 이때 활용하는 기능이 Redis의 TTL 기능(만료 시간 설정 기능)이다.
- TTL이 설정된 데이터는 설정한 시간이 지나면 자동으로 Redis에서 삭제된다. 이후 특정 사용자가 조회하는 순간 Cache Miss가 발생하게 되고, DB에서 데이터를 새로 조회해 Redis에 다시 저장한다. TTL을 통해 데이터를 주기적으로 갱신할 수 있게 된다.
저장 공간 크기 문제
a. 한계
DB는 디스크에 저장하기 때문에 많은 양을 저장할 수 있지만, Redis는 메모리에 저장하기 때문에 DB에 비해 많은 양을 저장할 수 없다.
b. 해결 방안 (TTL 기능)
위에서 말한 TTL 기능을 활용하면 주기적으로 Redis가 비워지므로 공간을 효율적으로 사용할 수 있다.
4. 캐싱으로 조회 성능을 개선하기 전 'SQL 튜닝'을 항상 먼저 해야 한다!
데이터 조회 성능을 개선하는 방법은 다양하다.
- SQL 튜닝
- 캐싱 서버 활용 (Redis 등)
- 레플리케이션 (Master/Slave 구조)
- 샤딩
- DB 스케일업 (CPU, Memory, SSD 등 하드웨어 업그레이드)
이때 많은 성능 개선 방법 중 'SQL 튜닝'을 가장 먼저 고려해야 하는 이유는 아래와 같다.
- SQL 튜닝을 제외한 나머지 방법은 추가적인 시스템을 구축해야 하므로 금전적, 시간적 비용이 발생하게 된다. 또, 조금 더 복잡해진 시스템 구조로 인해 관리 비용도 늘어난다. 그에 비해 SQL 튜닝은 기존의 시스템 변경 없이 성능을 개선할 수 있다.
- 근본적인 문제를 해결하는 방법이 SQL 튜닝일 가능성이 높다. SQL 자체가 비효율적으로 작성됐다면 아무리 시스템적으로 성능을 개선한다고 하더라도 한계가 있다. SQL 튜닝을 통해 기본적인 성능을 향상한다면 시스템적인 성능 개선이 필요 없거나 훨씬 간단하게 큰 성능 개선 효과를 얻을 수 있다.